List of Figures
- Figure 0-1: Author struggling to keep the world they build — p. 8
- Figure 0-2: Augmented author focused on story progression as AI keeps the world stable. — p. 8
- Figure 3-1: Manual Canon Curation — p. 17
- Figure 3-2: Automated Canon Curation — p. 18
- Figure 3-3: Canon Adherence Through LLM — p. 19
- Figure 3-4: Reader's Mental Process — p. 20
- Figure 3-5: World Engine Simulation of Reader's Mental Process — p. 21
- Figure 4-1: Story upload and Processing Sequence — p. 24
- Figure 4-2: API Request Processing Sequence — p. 24
- Figure 4-3: Plot Consistency Implementation Analogy — p. 28
- Figure 4-4: A summary of Plot Consistency Implementation — p. 30
- Figure 4-5: A summary of Canon Adherence Implementation — p. 32
- Figure 4-6: A summary of Continuity Accuracy Implementation — p. 34
- Figure 4-7: Logical Flow of events while checking for World Rule Violations — p. 36
- Figure 4-8: A summary of World Building Integrity Implementation — p. 37
- Figure 4-9: A Concise Summary of All Objective Implementation — p. 38
- Figure 5-1: Plot Consistency analysis sample on the Wizard of Oz — p. 42
- Figure 5-2: A Sample Canon Synthetic Truth Extract from The Strange Case of Dr. Jekyll and Mr. Hyde — p. 44
- Figure 8-1: Research and Professional Ethics Certification of Completion — p. 51
List of Tables
- Table 1: A summary of Methodology for each Objective — p. 22
- Table 2: Unit Testing on Key Functions — p. 38
- Table 3: A Sample of Canon extracts from The Strange Case of Dr. Jekyll and Mr. Hyde — p. 42
List of Algorithms
- Equation 1: Synthetic Truth Logical Consistency Score (STLCS) — p. 17
- Equation 2: Continuity Accuracy Metric (CAM) — p. 17
- Equation 3:Canon Adherence Score (CAS) — p. 18
- Equation 4: 3.1.4 — p. World Integrity Score (WIS) — p. 18
- Equation 5: Collapsible Conflict Segment — p. 28
- Equation 6: Pagination of Violations — p. 28
- Equation 7: WIS — p. 48
List of Appendixes
Evaluator.py
Lore_engine.py
ABSTRACT
This paper proposes a web-based application with Artificial Intelligence (A.I) features designed to manage the Synthetic Truth (S.T) of fictional worlds in which stories are told. ‘Synthetic Truth’ refers to Statements that are True only within the confines of an imagined reality.’
The application functions to manage physical, chemical and biological S.T logic, plot consistency, continuity accuracy, canon adherence and worldbuilding integrity.
Plot consistency: When a character establishes a fact, said fact shall not be disputed without a causal link.
Example: In Chapter 4, the protagonist says, “My oxygen tank was ruptured –I only had 60 seconds left to live.” A few pages later, without any explanation, “they wander Mars’ surface for 20 minutes having a conversation.”
This breaks plot consistency, as the immediate danger established by the oxygen limit is ignored without any causal link (e.g., finding a spare tank, or switching to a suit with a backup system).
Worldbuilding Integrity: When an imagined world has a set of principles governing it, said principle should be maintained across the story.
Example: In a fictional world where magic is powered exclusively by sunlight, a character casts a powerful spell during the night in an underground cave with no access to sunlight.
This breaks worldbuilding integrity, because the story has already established that sunlight is the sole source of magical power. For this moment to remain consistent within the Synthetic Truth of the world, either the principle must be updated with a causal explanation (e.g., the character stores sunlight in crystals or specialized sunlight organs for later use), or the spellcasting must be altered to occur under valid conditions.
Continuity accuracy: Details are to remain logically consistent throughout a story's timeline, such as character injuries, clothing, weather, or object locations.
Example: In Chapter 6, a character loses their left eye in a battle and receives a distinctive silver eyepatch. In Chapter 9, set just two days later, they are described as having both eyes intact and no mention of the eyepatch is made, despite it being a key character feature.
This is a continuity error, because there is no narrative explanation (e.g., regeneration, illusion magic, or memory tampering) provided to reconcile the change with the previous state.
Canon adherence: Consistent respect of established facts that synthetic truth. Example: In chapter 1 of a manuscript, it is clearly established that the alien species Zarans are blind and rely on echolocation to navigate. This is emphasized multiple times, including a key scene where a Zaran says, “We do not see as you do. Sound is our sight.”
In Chapter 3, a Zaran pilot looks through a telescope and says, “I can see the Earth’s surface from here. It’s beautiful.” No explanation is given, and the story proceeds as if Zarans have always had visual sight.
Through Object-Oriented software development combined with Top-Down designing for planning and system-centered evaluation testing (quantitative + qualitative error analysis), this study will create an application capable of identifying and keeping track of said objectives.
Figures
Authoring workflow (before vs after)

Figure 0-1
Author struggling to keep the world they build from imploding.

Figure 0-2
Augmented author focused on story progression as AI keeps the world stable.
Chapter 1: INTRODUCTION
Storytelling has long been one of the most powerful tools through which humans may express themselves. They shape culture, preserve history, put complex knowledge into perspective, inspire innovation and provide entertainment across generations.
Fictional narratives – In whatever form they are presented in; novels, games, or multimedia franchises – are increasingly vast and complex, often spanning multiple timelines, character arcs, and interconnected worlds. While these elaborate constructions offer unparalleled richness, they also present a significant challenge: maintaining logical and structural consistency within the narrative. Readers engage with stories by immersing themselves in their internal logic, and any violation of that logic can disrupt immersion, weaken suspension of disbelief, and erode confidence in the author’s craft or attract criticism from dedicated fans towards the institutions developing a story.
The problem of narrative inconsistency is particularly acute in long-form, collaborative storytelling and in the works of many novice authors. Issues such as contradictory plot developments, misaligned timelines, characters acting in ways that defy previously established canon and forgotten continuity states such as objects declared destroyed in one scene appearing in another or a character’s past accidentally misremembered are common even in widely celebrated works. For instance, the later seasons of were heavily criticized for narrative contradictions, and the franchise required a canon reset to manage inconsistencies across its extended universe.
These examples illustrate that even professional authors and studios struggle to sustain stability in fiction across sprawling fictional worlds that expand faster than the creators can track them. Especially so in institutionalized settings where writers’ room grow and staff rotation fragments institutional memory. This leads to creators often at times relying on ‘Canon bibles’, style guides or fan wikis and archivists to keep track of their own fiction.
Breaks in a fiction’s stability harm the bottom line of any studio or institution responsible since immersion loss damages the audience’s trust and emotional investment which is expressed in reduced engagement, criticism and bad reviews hence harming the merchandise market and licensing revenue.
In summary, fictional worlds are delicate ecosystems; they grow fast, get chaotic and become too complex for manual tracking. The theoretical foundation for addressing this challenge lies in Narratology, Possible Worlds theory and Large Language Models. Structural narratology breaks narratives into analyzable units –such as plot, character, and timeline – that can be systematically studied for coherence. Cognitive narratology extends this analysis to the reception of narratives, emphasizing that readers actively construct mental models of fictional worlds while processing stories. Within Possible Worlds theory, fictional universes are treated as logically self-contained systems, where propositions can be evaluated for internal truthfulness. From this perspective, inconsistencies represent violations of the world’s Synthetic Truth, the “reality” that holds within its fictional boundaries.
Despite the theoretical sophistication of narratology and related fields, authors today rely largely on manual tools to maintain consistency: personal notes, spreadsheets, wikis, or even fan-driven knowledge bases. These approaches, while valuable, are prone to human error and become increasingly inadequate as narratives grow in scale and fact-checking and world-coherency reviews are ignored in favor of meeting deadlines.
Existing computational aids for writers have primarily been generative –language models that suggest text or dialogue – rather than evaluative, that is, capable of detecting contradictions, canon breaks, or logical gaps on demand. This gap highlights an opportunity for artificial intelligence to provide substantive support in narrative evaluation.
Recent advances in Natural Language Processing (NLP) and Large Language Models (LLMs) make this possibility increasingly feasible. Embedding models allow machines to capture semantic relationships across narrative elements, while LLMs approximate human reasoning about coherence and contradiction. In effect, AI can be leveraged to verify a fiction world’s logical integrity instead of story generation. This firmly reframes the research frontier, moving from content generation towards computational validation of world integrity.
This thesis proposes a narrative integrity evaluation software – World Integrity Engine–, a system designed to assist authors (professionals, novices and indie authors) and studios in identifying breaks and inconsistencies in their works without intruding on their creative process. The framework evaluates narratives across four defined objectives: plot consistency, ensuring that causal and temporal links remain coherent; continuity accuracy, validating that timelines, events, and character states progress logically; canon adherence, checking that established rules and lore are not violated; and worldbuilding integrity, assessing whether implied and explicit world structures interact coherently.
The contribution of this work lies in demonstrating that AI methods can operationalize these objectives, offering authors and studios a tool that reduces cognitive burden while enhancing narrative quality even for novice authors. In doing so, the research bridges Narratological theory, Cognitive science, and computational techniques, showing that artificial intelligence can extend beyond generation into the uncharted grounds of fiction-world verification.
The remainder of this dissertation is structured as follows. Chapter 3 reviews the existing literature in Narratology, Cognitive Science, and AI-based narrative analysis. Chapter 4 details the methodology and system design of the evaluation engine. Chapter 5 presents the implementation and testing of the system using selected short stories. Chapter 6 discusses the findings, their implications, and limitations. Finally, Chapter 7 concludes with reflections on contributions and recommendations for future research.
AIMS AND OBJECTIVES
Aim:
To design, develop, test and deploy a web-based application system with AI tools specifically designed to detect, highlight and quantify the integrity of a fictional world.
Objectives:
- Define the term ‘Synthetic Truth’ and its role in bridging implementation of the proposed Author-Machine dynamic.
- Build a web application that keeps track of
- Plot consistency
- Continuity Accuracy
- Canon Adherence
- Worldbuilding Integrity
- Introduce and Implement sets of metrics such as Synthetic Truth Logic Consistency Score (STLCS), Continuity Accuracy Metric (CAM), Canon Fidelity Index, and World Integrity Score (WIS).
- Test the System with freely available stories from indie publishing websites, freely available stories from novice authors and freely available stories from professional authors.
Chapter 2: LITERATURE REVIEW
The challenges plaguing narrative coherence within the ever-expanding fictional universes have been documented across Narratology, media studies, and production research. explores how the audience constructs “storyworlds” from given narrative cues. A ‘storyworld’ being a mental model whereby maintaining internal consistency and coherence are critical since they allow the audiences’ mental models to remain stable and immersive. In this way, it can be seen that stories aren’t simply sequences of events but are instead, rule-based simulations with cause-effect logic and ontological coherence.
in what the researcher called ‘Transmedia Storytelling’ addressed how narratives are being told across different media. A book, turning into a comic which is then made into a film or animation then also made into a game. Though it increases engagement from the audience, it also creates major coordination challenges since no single media contains the entire story. Instead, each media contributes disparate portions of the narrative and audiences assemble the aggregates into a wider world. Different creative teams, production cycles and corporate structures have to harmonize and maintain a shared canon. warns that the audience’s active participation invites more scrutinization and without rigorous oversight, contradictions, continuity gaps and lore fragmentation will result in hash backlashes from the audience that often at times police story development more strictly than studios.
goes further and highlights the complexities in fiction world building and how they are sustained by creating a distinction between the story ( Sequence of events ) and the world (The underlying environment, rules, systems, geographies, histories, cultures etc ); arguing that the world-building is an ongoing system-level art rather than a single creative process, the foundation from which stories are built. A single world could be host to a myriad of stories. Changes done to the very foundation ripples across media forms and affects the progress of other stories built upon the same foundation or a single story being told across different media.
A good example is where the world foundation has outgrown the original story it supported. It has expanded and goes beyond a simple narrative about “a boy with a scar” into a sprawling transmedia creation. As and described, ‘transmedia storytelling’ disperses a narrative across multiple platforms, with each new text contributing distinct elements to a shared universe. What this paper describes as Synthetic Truths. What began as seven novels charting Harry’s coming-of-age has since expanded into a network of stories that are often interlinked yet they aren’t necessarily narratively contingent upon one another: the film series, stage play, spin-off books like and , video games, theme park experiences, and lore-focused platforms such as . These works often do not center Harry at all but are still stories that operate within the same Wizarding World framework; making the original books just one narrative thread among many that rely on the Wizarding World foundation to tell their stories. This shift illustrates how a fictional property can outgrow its genesis story and become a persistent, multi-author world, where managing continuity and canon becomes significantly more complex.
Narratology, especially when viewed through the lenses of structural narratology, grounds part of the theoretical framework of this research and the novel solution derived from it. Structural narratology as described by , compartmentalizes story narration into analyzable component structures such as plots, timelines and arcs. This decomposition of Narration enables a systematic evaluation of internal consistency across different narrative dimensions such as settings, characters and themes. By viewing stories as structured systems, narratology makes it possible to identify and assess logical coherence within fictional texts.
This study also builds upon the findings of Cognitive Narratology, where the focus expands from the sphere of narrative creation and into the domain of reader reception. argue that readers mentally construct meaning while interacting with a story. This can be viewed as readers simulating worlds of the literal narratives they read in which the elements of the narrative form core logics of the world. Violating this inferred narrative coherent truth, such as unexplained contradiction, disrupts immersion, weakening the narrative.
Innovation for the proposed solution comes from a recent empirical study by the in collaboration with UK which provides a strong precedent for the use of large language models in qualitative narrative analysis. The researchers tested two models (Claude and GPT-o1) against human analysts on a corpus of 138 short stories written by young people. Each model replicated the analytic steps of human narrative research, with findings judged to be both credible and thorough. Notably, the models also generated ‘additional interpretive insights’ that enhanced the ‘human’ analysis, suggesting that LLMs can function not only as replicators but as augmenters of traditional qualitative approaches.
Though their study raises important questions on ethical governance and methodological transparency, this is only in relation to the extrapolation of this study into other facets of the real world and not this study’s current focus, which is the Authoring of fictional worlds. What their study brought to light, however, was the potential of LLMs to strengthen not only research quality and efficiency through narrative analysis but also the quality and speed of narrative stability verification and management of canon sprawls.
Earlier, the term Synthetic Truth was used. ‘Synthetic’ according to Wiki, is defined as “that which is Artificial, Not Genuine.” While ‘Truth’ is ‘genuine depiction or statements of reality.’ Together, Synthetic Truth (S.T) stands to mean ‘Statements of reality within the confines of an imagined universe.’ The very building blocks that make up the foundations upon which stories are built.
argue that, should we compartmentalize the abilities of the cognitive agent block, then ‘creativity’ would be packaged as one of many services to be called upon by the block. The paper further contrasts these cognitive services with modular, distributed web systems; suggesting that they both exhibit the same complexities in implementation, diversity and structure.
explored the feasibility of Artificial Intelligence modeling creativity. A.I showed its competence in analyzing existing creative products such as jokes and computing possible new products of creativity. The paper established two major problems that stood in the way of AI creativity: a lack of domain expertise and AI’s inability to evaluate its own creativity.
Both papers give credence to the proposed research. Combining what these two entities do best resolves the bottlenecks faced by them individually. Authors, studios and creative teams fill the role of creativity while LLMs alleviates the computable cognitive burdens that come with being a creative.
Explores some of the greatest modern fictional works like , , and with their sprawling worlds, complex histories and intersecting storylines. These stories’ complexities were so grand that also explored how authors saw it necessary for “Collaborative Worldbuilding for Writers and Gamers”, describing how writers can co-create vast worlds for use of their own stories.
This paper aims to prove that every author could potentially create one of these grand worlds by making use of AI as the cement holding their story together.
finds it necessary to split world-building into two branches. The first branch focuses on the architecture of a world while the second branch explores how the disparate building blocks interact with each in both explicit and implied ways.
Hence world building becomes an iterative process where the author reviews both branches to not only flesh out the story but also review strategies, maps, ideological and political approaches.
Chapter 3: RESEARCH METHODOLOGIES AND TOOLS
Research Design
This project will take on a hybrid approach. A combination of Object-Oriented software development and Top-Down planning and designing.
The system will process a curated dataset of fictional texts –Including both consistent and intentionally flawed narratives — to demonstrate the software's ability to detect contradictions, lore violations, and semantic inconsistencies.
was used to create the illustrations included throughout this research.
The following metrics will inform the quantitative aspects:
Synthetic Truth Logic Consistency Score (STLCS)
A set of S.T laws; ─for example gravity, energy conservation, biological evolution, chemical reactions─ shall be assigned a consistency score (0-100) by the AI based on the number of violations detected in a story. (Consider adding name as author- all equations have been designed by author- part of contribution)
Equation 1: Synthetic Truth Logical Consistency Score (STLCS)
Example: 4 violations out of 10 S.T statements then the result shall be 60% Consistency.
This is further divided into Physical Violations, Chemical Violations, Biological violations, Timeline Violations, Technological Violations, Economical Violations, Knowledge Violations and Medical Violations.
Continuity Accuracy Metric (CAM)
This measures crucial details across a story such as object states, character positioning, room orientation or scene descriptions if they’ve been mentioned more than once.
State Loging shall keep track of these details across chapters and compare them to their last known states. Illogical Contradictions based on the established S.T laws shall be flagged.
Equation 2: Continuity Accuracy Metric (CAM)
Canon Adherence Score (CAS)
Canon Adherence Score is a measure about fiction-specific laws: races, histories, artifact.
Definition: Canon facts are statements the text has previously defined as absolute within its fictional world.
Example: “Only elves can wield the Moonblade.”
Which is calculated by:
Equation 3:Canon Adherence Score (CAS)
World Integrity Score (WIS)
World elements such as location, climate, cultural norms, geographical elements, physical laws, political borders and power structures shall be vectorized. WIS is a measure of the average semantic deviation of these vectorized elements over multiple mentions of it in the story.
Equation 4: 3.1.4 World Integrity Score (WIS)
OBJECTIVE 1: PLOT CONSISTENCY (STLCS)
Plot consistency is the evaluation of whether story events remain logically consistent with previously established narrative claims. This includes character actions, cause-and-effect relationships, and continuity of events across chapters. A contradiction occurs when a later event invalidates or reverses an earlier claim without explanation (e.g., “The Sword of Alchemy was destroyed.” → “Aran drew the Sword of Alchemy.”).
Implementation methods considered:
Event Timeline Tracking: Manually or automatically constructing a timeline of events, then testing each new event against the timeline.
Causal Link Modeling: Using LLMs to infer causal dependencies (“X happens because Y”), and flagging violations when causes are ignored.
Claim Extraction + Contradiction Detection (chosen approach): Extract all critical claims from each chapter, then compare new content against stored claims to detect contradictions.
The third approach mirrors how readers process stories: they form mental “claims” (facts about what has happened, what is true or what is considered relevant) and updates them as the story progresses. The LLM automatically extracts such claims in forms like:
“X is alive” / “X died”
“The artifact was destroyed” / “The artifact is being used”
“A journey takes weeks” / “The same journey was completed in a day”
Contradiction detection is performed by comparing new chapter claims with the previously extracted set. This yields both:
Score (STLCS): percentage of claims violated.
Violations: explicit contradictions (stored with claim, conflict segment, GPT reasoning).
OBJECTIVE 2: CANON ADHERENCE
Canon adherence is the measure of new story contents against previously established Synthetic truths. ( Facts of the Fictional World. ) For example: species traits and historical events. These Synthetic truths determine how the world functions and violation of them breaks the internal logical consistency of the narrative.
Three implementation methods were considered:
- Manual Canon Curation: Defining the world rules in the first two chapters, against which new story elements would be scrutinized against.
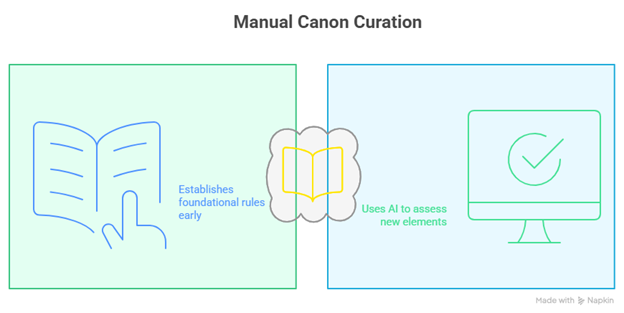
Figure 3-1: Manual Canon Curation
- Automated Canon Curation: Let the LLM extract the facts from early chapters and store them under the “Canon” category.
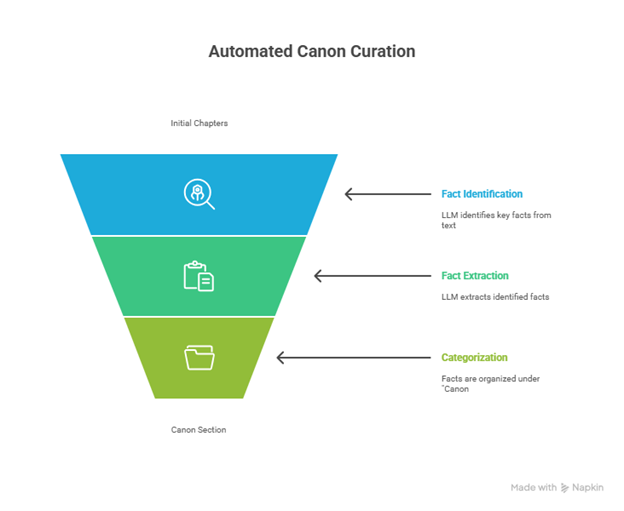
Figure 3-2: Automated Canon Curation
- Automated Extraction of Elements of Certainty: Let the LLM extract Synthetic Truths in the form of phrases of certainty. Example: “Magical beasts’ Evolved forms have no eyes.”
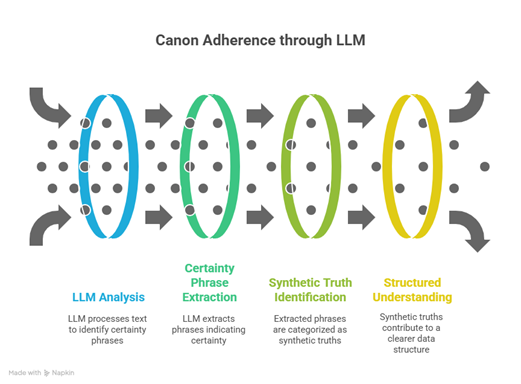
Figure 3-3: Canon Adherence Through LLM
The third, hybrid-approach, which is one of this paper’s novel contributions, was chosen since few authors define the entirety of the world within the first couple of chapters. Instead, it’s often an evolving world. Some important lores are revealed later in stories making automated curation from the first couple of chapters inadequate.
Proceeding with the third methodology, there are three sentence structures the LLM will be on lookout for:
- General Truths in the fictional world. Example: “Pink Martian skins.”
- Confident declarations by narrators or by characters.
- Definition of rules, abilities, races and limits.
Common canonical phrasing patterns that shall be considered are:
- [Entity] are [Property] : "Zaratans are blind"
- [Concept] always [Behavior] : "Cosmic mana always requires sunlight"
- [Group] cannot [Action] : "Zaratans cannot see"
- No one can [Action] without [Condition] : "No one can use magic without a conduit"
- Only [X] can [Y] : "Only queens can enter the throne room"
- It is impossible to [Action] : "It is impossible to breathe on Mars without a suit"
The methodology to achieve objective 2 shall boil down to mirroring a reader’s mental process:
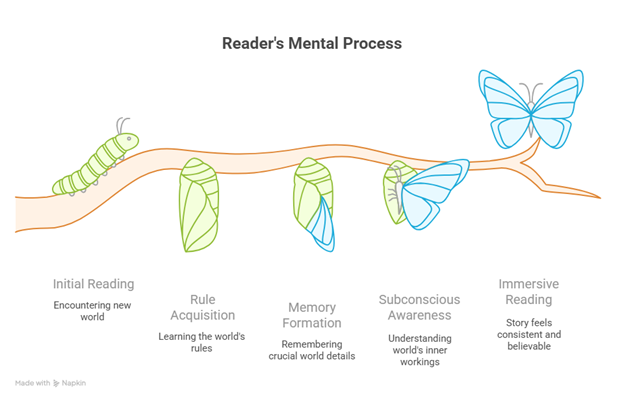
Figure 3-4: Reader's Mental Process
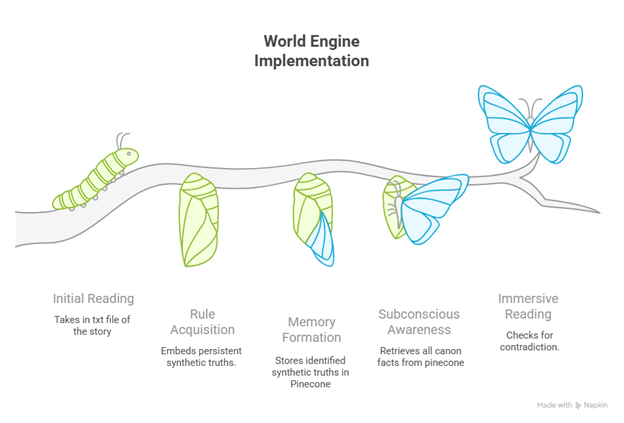
Figure 3-5: World Engine Simulation of Reader's Mental Process
OBJECTIVE 3: CONTINUITY ACCURACY
Continuity accuracy ensures consistency of details across a story. Details such as names, places, timelines, and descriptive facts are elements easily forgotten. Unlike canon (world truths) and plot (event causality), continuity focuses on factual details that should remain stable once introduced. For example:
- A character’s eye color, weapon or name changing mid-story without explanation.
- Distances and travel times shifting inconsistently.
- Dates, ages, or titles mismatching across chapters.
Three implementation methods were considered:
Index-based Tracking: Storing all details in a structured index (characters, items, places), then flagging mismatches.
Vector Embedding Search: Embedding continuity claims and searching for near matches when new content appears, to detect mismatches.
Hybrid Extraction + Comparison (chosen approach): Extract continuity facts per chapter, embed them, and compare against all stored facts to flag inconsistencies.
Hybrid Extraction + Comparison The LLM extracts “continuity facts” expressed in stable forms like:
“[Entity] has [Property]” (e.g., “Ola has blue eyes, Orange hair and fair skin”).
“[Place] is located in [Region]”. (e.g. ).
“[Time period] lasted [Duration]”. (e.g The waning era lasted three hundred years.)
Later text is scrutinized against this ‘database of facts’. Violations are then spotted and returned as:
Established Fact: which is the original claim.
Conflict Segment: The passage causing contradiction.
Explanation: The LLM reasoning when flagging the event as a violation of continuity.
OBJECTIVE 4: WORLD BUILDING INTEGRITY
This involves the measure of a story remaining true to the systems that are its underlying framework. Example: Power Systems, Ruling systems, Magic Systems, Economic Systems, Justice Systems.
Implementation methods considered:
Rule-First Author Annotation: Authors manually define rules (e.g., “magic requires mana”), against which violations are checked.
Automated Rule Extraction from Narrative: LLMs extract “if-then” or “only-when” structures that imply rules.
Hybrid Rule+Violation Evaluation (chosen approach): Extract rules automatically, track them, then check story content for violations.
This research went ahead with the hybrid solution. The LLM will search for rule-like phrasings:
“Only X can Y” → “Only priests can enter the temple.”
“To do X, Y is required” → “To cast fire magic, spark mana is required.”
“It is forbidden to X” → “It is forbidden to carry weapons in the palace.”
Violations would be flagged when new content breaks these established constraints without explanation. Results include:
List of rules and systems (worldbuilding skeleton such as currency, history, rulership philosophy etc).
Integrity score (WIS score).
Violations (rule broken, conflict segment, GPT explanation).
This mirrors a reader’s sense of immersion: once the rules of a fictional world are understood, any unacknowledged violation immediately weakens believability.
SUMMARY
Table 1: A summary of Methodology for each Objective
| OBJECTIVE | EXTRACTS FROM TEXT | CHECKS FOR | EXAMPLE VIOLATION |
|---|---|---|---|
| Plot Consistency | Factual claims/events | Logical contradictions | Dead king suddenly speaks again |
| Canon Adherence | Hard canon facts | Breaks of lore | Human uses elf-only artifact |
| Worldbuilding Integrity | Systemic rules/mechanics | Physics/magic/economy broken | Magic working in void space when it shouldn't |
| Continuity Accuracy | Character/state/timeline facts | Inconsistencies in state/timing | Item lost in Ch3 reappears in Ch6 unaddressed |
Chapter 4: Design and Development
Introduction
At the highest level, the front end receives the text file from the user. It then sends the file to an API, which then sends the text information to the backend. The backend houses other Django applications. The one that receives the text from the file is called Core. Within Core are functions that are dedicated to meeting this research’s objectives.
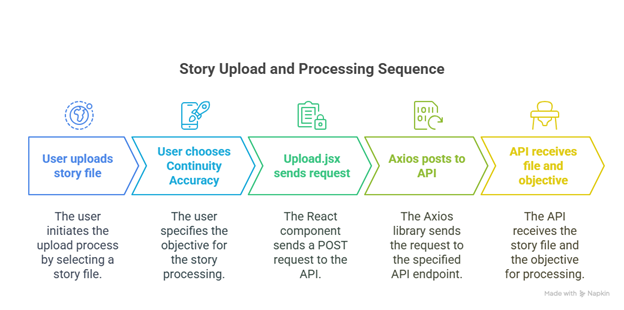
Figure 4-1: Story upload and Processing Sequence
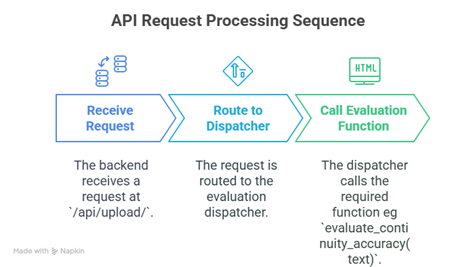
Figure 4-2: API Request Processing Sequence
Results Presentation
The frontend was developed in with as the build tool and for styling. Its primary role is to present the outputs of the analysis functions and their respective metrics (e.g., evaluate_plot_consistency, evaluate_canon_adherence, evaluate_continuity_accuracy, and evaluate_world_integrity).
The design was built around three principles:
Transparency – This involves showing the reasoning steps taking place and involves elements such as claims, conflicts, LLM reasoning explanations.
Readability – Large volumes of text need structuring such as pagination and collapsible cells.
Traceability – Each result links back to its originating “Synthetic Truth” for easy inspection.
Component Structure
Each research objective is represented by a dedicated React component:
STLCS.jsx (Plot Consistency)
Canon.jsx (Canon Adherence)
ContinuityTable.jsx (Continuity Accuracy)
WorldIntegrityResults.jsx (Worldbuilding Integrity)
Each of these follows the same high-level structure:
Render the metric score in a highlighted card or table.
Show extracted Synthetic Truths (rules, canon elements, continuity details).
Display violations of Synthetic Truths in a tabular format.
Interactive features such as collapsible cells and pagination.
Key Features
Chunk-Level Fact Presentation Extracted rules and facts (e.g., “Martians cannot see”) are rendered in list or table format. They are color-coded based on whether they are respected or violated.
<td className={violated ? "text-red-600" : "text-green-600"}>
{violated ? "Violated" : "Respected"}
</td>
Collapsible Conflict Segments Violating text segments can be lengthy. To avoid overwhelming the reader, they are truncated with a “Show more / Show less” toggle. This let’s the author glance over results but diving deeper when needed.
Equation 5: Collapsible Conflict Segment
const [expanded, setExpanded] = useState(false);
<div onClick={() => setExpanded(!expanded)}>
{expanded ? conflict : conflict.slice(0, 120) + "..."}
</div>
Pagination for Violations Some stories generate dozens of violations. Pagination was added to maintain a clean interface while still allowing full inspection.
Equation 6: Pagination of Violations
const perPage = 10;
const currentViolations = violations.slice((page-1)*perPage, page*perPage);
Inline Loading Indicators Background tasks (story uploads, evaluation) can take time. An inline loader (<Loader />) was included to communicate progress to the user, preventing uncertainty when they are left in limbo while the program runs.
Example: World Integrity Results
A key React component is WorldIntegrityResults.jsx. This aggregates the World Integrity Score (WIS), lists the rules extracted from the story, and paginates through violations. The layout is designed so a researcher can immediately see:
The global integrity score.
What rules were assumed.
Where those rules were broken.
This mirrors the backend logic (fact extraction → embedding → contradiction check), but presents it in a human-readable flow.
All in all, the frontend was designed to mirror the percieved cognitive process of a critic looking for flaws or a dedicated audience:
- Recall established rules (Extracted Facts).
Skim for contradictions (Violation List).
Drill down when inconsistencies appear (Collapsible Conflicts).
Objective 1: PLOT CONSISTENCY
evaluate_plot_consistency(text) was the first function to have been developed to meet the first objective of this research. The function must investigate the text, find new events within the story, then look for parts that contradict earlier stated facts without a linking causality hence violating the synthetic truth of the world.
The flow of logic within this public function is in three parts:
- Extract important claims
- Store them as facts semantically
- Compare later chunks to detect logical contradictions.
These logical parts were then programmed into private methods.
split_into_chunks(text): The text is spilt into chunks of a thousand (1000) words which allows for long text analysis in manageable chunks. There is also a limit on context/tokens LLMs and embeddings have, so working in sections keeps processing efficient.
extract_critical_claims(chunk): Direct usage of OpenAI’s ChatGPT, though convenient, is expensive. Therefore, indirect usage of the resource through Microsoft Azure OpenAI which offers 200$ credit to new users, was necessary.
Important facts are extracted from these chunks which will later be used to determine whether a plot consistency violation has occurred, a measure of which gives STLCS.
Example:
“In Chapter 4, she removes her helmet on Mars and says, ‘I can breathe here’.”
Response:
- Claim: The atmosphere on Mars is breathable without a helmet.
- Source: “she removes her helmet on Mars…”
- Reason: This defines a Synthetic Truth physical law –(A Physical law that remains true only in context of the fictional world).
store_fact(category, text, chapter, story_id="default"): The extracted Synthetic Truths are embedded via Azure text-embedding-ada-002 and stored in Pinecone. Metadata passed in the function tags each identified Synthetic Truth with categories such as Plot and Chapter number i.
The reason we go with vector embedding instead of traditional database storage is that we need the retrieval of similar ideas even when worded differently. This is essential in our use-case as we aren’t searching for contradictions yet. Instead, we are grouping similar ideas even when phrased or expressed differently.
Once this is done, we loop through all chunks while comparing every newer chunk’s Synthetic Truths to previous ones. Having determined the direction of investigation, the actual search is done through a vector search. This shall pull synthetic truths that are semantically close to the current chunk.
This is referred to as inter-chunk consistency checks which are checks across multiple chunks.
Intra-chunk consistency checks are unnecessary since they add unneeded complexity to the project while having very little impact. The chunks are already split into approximately a thousand words, which is the approximate length of a chapter. An author is capable of maintaining local consistency within such a small scope, because contradictions inside a single scene are rare compared to narrative contradictions across the entire story. Most violations worth detecting (plot holes, canon violations, Continuity errors, world systems breaks) only emerge over multiple chunks.
is_contradiction(claim, chunk): Another request is then posted to gpt-35-turbo-evaluator, and within it, we pass the both the synthetic truth and the identified chunk that is semantically close. This second request is necessary since, even though a vector search brings related context together, only gpt-35-turbo-evaluator can apply nuanced reasoning to tell whether the events are contradictory.
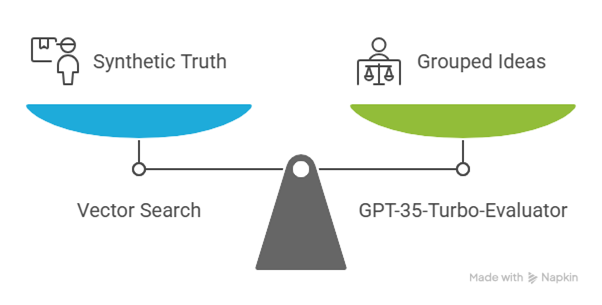
Figure 4-3: Plot Consistency Implementation Analogy
evaluate_plot_consistency(text): follows how a reader reasons while reading a story. First, they vaguely remember what they know about an event or the world itself, then they compare these vague memories to new events within the story and finally, they reason whether the new event makes sense.
Azure embedding model ─ embedding-ada-002 ─ extracts the meaning of a Synthetic Truth and not the Synthetic Truth itself. This meaning is then stored in pinecone. Pinecone grants us the capability to remember meanings that are closely related or directly connected. This is similar to how a reader has vague memories of the events or world in general. Vectors in close proximity to each other could indicate semantically related or potentially contradictory contexts.
Therefore, a second call to gpt-35-turbo-evaluator will apply causal reasoning to determine whether a contradiction exists between the passed vectors.
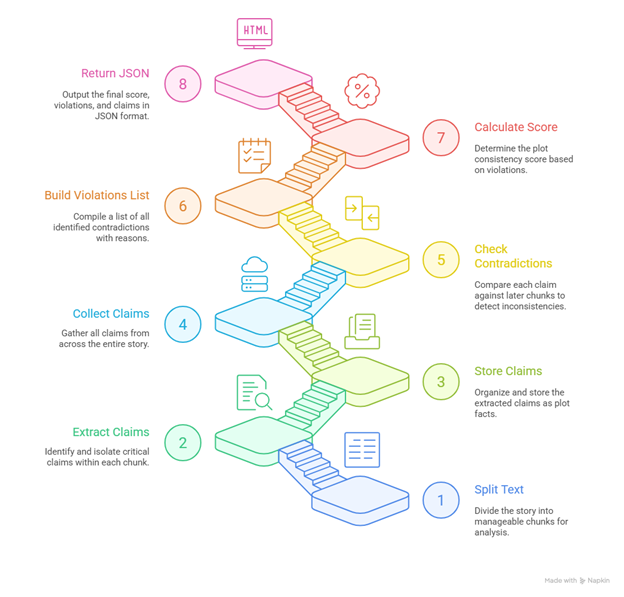
Figure 4-4: A summary of Plot Consistency Implementation
Objective 2: CANON ADHERANCE
chunks = split_into_chunks(text)
The text is split into chunks to allow for fine-grained analysis.
canon_facts = extract_canon_facts(chunk)
A prompt is used to extract only authoritative statements. Synthetic truths that serve as permanent pillars that hold up the story. Examples: Physics, magic, science
Example response from model:
- Canon Fact: Sun mana requires direct sunlight
- Canon Fact: Humans cannot breathe on Mars unaided
store_fact("canon", fact, chapter=i, story_id=story_id)
After the canon facts are extracted, they are converted to vectors by Azure’s text-embedding-ada-002 which are then stored in pinecone. The story id was added later in order to differentiate between canon facts in different stories. This function is a reflection of a reader’s internalization process of world rules.
canon_vectors = search_nearby(category="canon", text="canon", story_id=story_id)
We now retrieve all that we know about the world and create a world model. Each story chunk is evaluated against the world model. The check is carried out by a prompt designed to identify contradiction.
Example:
Canon Fact: Sun mana requires direct sunlight
Story Segment: The mage cast a sun mana spell deep inside the cave.
"Yes, the story contradicts the canon because sun mana needs sunlight, and no such condition is mentioned in the cave."
Every contradiction is logged for the author’s evaluation. Within the log; the excerpt, the canon violation and gpt-35-turbo-evaluator’s reasoning are recorded.
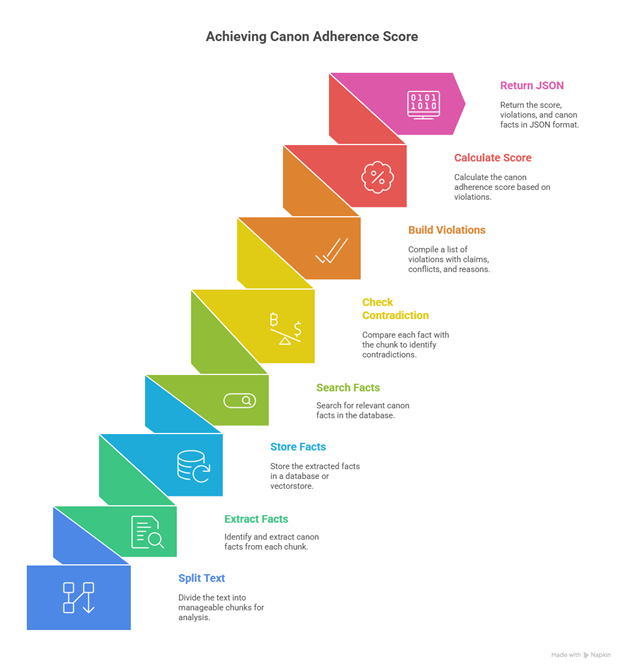
Figure 4-5: A summary of Canon Adherence Implementation
Objective 3: CONTINUITY ACCURACY
chunks = split_into_chunks(text): The text is first split into thousand-word chunks to allow for fine-grained analysis. This allows for tracking of stateful information such as characters, objects, locations or timelines across a narrative.
continuity_facts = extract_continuity_facts(chunk): A prompt is used to extract all states defined or mentioned in each chunk. These include any declarations of position, condition, possession, time, or relationships. These are, essence, information that has to remain consistent across chapters similar to how reality remains similar unless acted upon by outside influence. For example, A cup left on the table in the evening, it is expected that said cup is still on the table the morning after unless acted upon by an external influence.
Example of responses from the model:
Continuity Fact: John’s sword was completely destroyed.
Continuity Fact: The queen is currently in hiding.
Continuity Fact: The crew’s ship had a leak after the battle.
store_fact("continuity", fact, chapter=i, story_id=story_id):These extracted state facts are embedded with and stored in . Metadata tags each fact with its chapter and story ID. This mirrors how a reader stores mental bookmarks of “current known states” as they read.
all_facts = search_nearby(category="continuity", text="continuity", story_id=story_id): All known continuity facts are then retrieved to build a state map of the world so far. Each new chunk is evaluated against this map using a specialized continuity contradiction prompt.
Example:
Continuity Fact: “John’s sword was blasted to smithereens!” (Happened in Chapter 3)
Story Segment: John parried the attack with his sword. (Happening in Chapter 6) Response: “Yes, this contradicts continuity: the sword was said to be destroyed in Chapter 3, yet it is used here as if intact.”
Each violation is logged for the author’s review. Logs include: the violated fact, the conflicting excerpt, and GPT-35-Turbo-Evaluator’s reasoning.
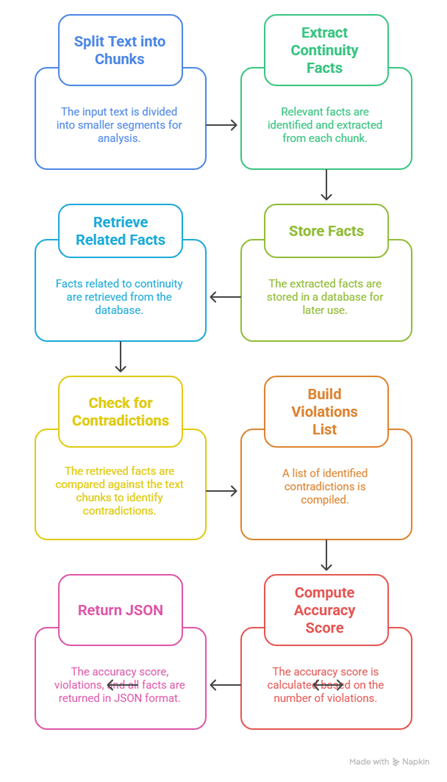
Figure 4-6: A summary of Continuity Accuracy Implementation
Objective 4: WORLD BUILDING INTEGRITY
chunks = split_into_chunks(text): The story is once again first split into thousand-word chunks to enable capilary analysis of the underlying mechanics of the world –Including its economy, climate systems, political hierarchies, and other global structures that must remain logically consistent.
world_rules = extract_worldbuilding_rules(chunk): A dedicated prompt then extracts foundational world rules from each chunk. These are systemic principles that govern how the world or universe operates and function as Sythentic Truths. They include elements such as currency, trade, laws, power or energy systems. These are all systems expected to remain consistent throughout the narrative or until an external influence acts upon them.
Below is a sample of the model’s example response:
World Rule: Crystal Shards are the only form of legal currency.
World Rule: 100 Shards = 1 Gold Bar.
World Rule: Foreign paper money has no value within the empire.
World Rule: The empire’s treasury strictly controls the supply of Crystal Shards.
store_fact("integrity", rule, chapter=chapter_title, story_id="default"): Each extracted rule is embedded via Azure’s text-embedding-ada-002 and stored in Pinecone under the WIS category and tagged with chapter and story ID. This step represents how a reader slowly builds a mental map of how the world systems work as they read.
integrity_vectors = search_nearby(category="integrity", text="rule", top_k=50): Once stored, all known rules are retrieved to construct a semantic world model. Each new chunk is then checked against this model using a world integrity contradiction prompt that flags any content that breaks the logic of the world’s systems.
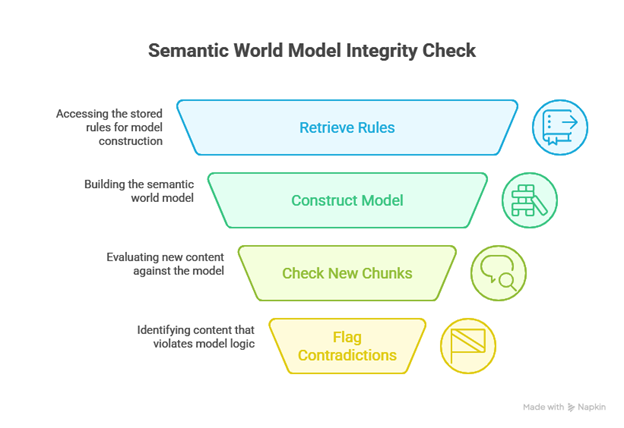
Figure 4-7: Logical Flow of events while checking for World Rule Violations
Example:
World Rule: Crystal Shards are the only legal currency.
Story Segment: The merchant prized the sword at “500 gold coins”. Response: “Yes, this violates worldbuilding integrity because gold coins were never introduced as valid currency, contradicting the established economic rules.”
Every violation is logged, recording the segment, the violated world rule, and GPT-35-Turbo-Evaluator’s reasoning.
The WIS is then calculated and given as a percentage score response reflecting how consistently the story adheres to its own defined world systems.
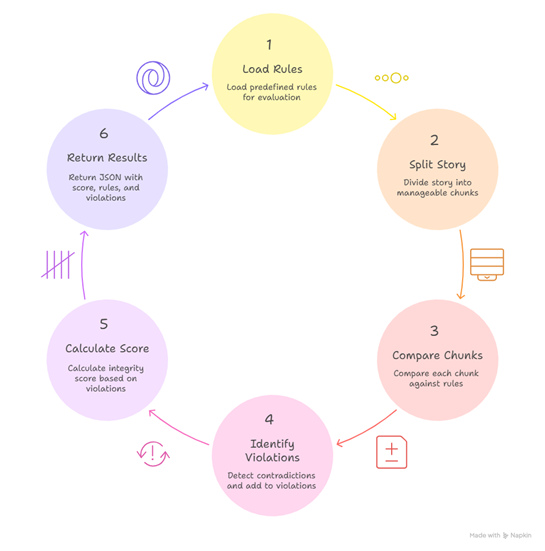
Figure 4-8: A summary of World Building Integrity Implementation
SUMMARY

Figure 8-1: A Concise Summary of All Objective Implementation
Chapter 5: Implementation and Testing
The system was implemented as a two-tier application, comprising a Django REST API backend and a React (Vite + TailwindCSS) frontend. The backend housed the four evaluation functions — evaluate_plot_consistency, evaluate_canon_adherence, evaluate_continuity_accuracy, and evaluate_world_integrity. Each function operationalized the conceptual design discussed in Chapter 3.
For instance, the plot consistency function follows the logic described in Section 3.2:
Splitting the text into chunks (split_into_chunks) for manageable analysis.
Extracting claims (extract_critical_claims) via an LLM hosted on Azure OpenAI.
Embedding claims using text-embedding-ada-002 and storing them in Pinecone with chapter-level metadata.
Cross-checking claims from earlier chunks against later ones through a semantic search (search_nearby).
Contradiction detection (is_contradiction) where GPT-4o-mini applies reasoning to judge violations.
This process translated directly into Python functions.
On the frontend, these results were displayed in interactive tables with pagination, collapsible cells for long conflicts, and status indicators for respected vs. violated facts. This allowed for an interpretable presentation layer for testing and validation.
Testing Strategy
The testing phase was structured around three major parts: unit-level testing, end-to-end integration testing, and simulation evaluation using real short stories from novice authors.
Unit Testing
Unit tests targeted private methods that collectively powered each objective’s analysis pipeline. These functions are foundational blocks of the WIE, and ensuring their correctness was essential before testing higher-level behaviors.
Table 2: Unit Testing on Key Functions
| FUNCTION | TEST PURPOSE | EXAMPLE TEST | EXPECTED RESULT |
|---|---|---|---|
| embed_text | Confirm embedding generation | "The sky is blue" | 1536-d vector returned |
| store_fact | Confirm correct insertion and metadata | "Dragons breathe fire" | Entry visible in Pinecone dashboard |
| search_nearby | Confirm semantic retrieval and filtering | search "fire breath" after storing above | Returns “Dragons breathe fire" |
| setup_logger | Confirm log creation per book title | "The_Lost_Colony" | Creates logs/The_Lost_Colony_x.log |
System Integration Testing
System-level tests validated the interaction between the React front-end, the FastAPI backend, and the underlying evaluation modules. The aim was to confirm that the system could handle realistic user interactions and end-to-end flows.
Key checks performed:
React → API Integration
Verified that file uploads were correctly transmitted using Axios and received as multipart form data.
Confirmed that the objective selection in the UI correctly mapped to the respective backend function (stlcs, canon, continuity, wis).
Backend Orchestration
Ensured that the correct evaluation pipeline was triggered, and that intermediate logs were created with filenames incorporating both the objective type and the uploaded book title for traceability.
Checked response structure from API: each evaluation returned a score, violations array, rules or array as expected.
Error Handling
Uploaded unsupported file types and empty payloads to confirm that graceful error messages were returned to the front-end without crashing the server.
Simulated network interruptions to ensure Axios promise rejection was caught and displayed to the user. Integration testing confirmed that all moving parts communicated correctly under realistic usage patterns, ensuring that failures in one layer (e.g., the API) did not cause silent failures in another (e.g., React UI).
Simulation Testing with Short Stories
Black-box simulation tests we finally carried out. The system’s ability to analyze real-world data under realistic operating conditions were evaluated.
The set up included selected 5 publicly available short stories (2,000–10,000 words each) from community sources such as SpaceBattles forums that contained known continuity breaks, shifting world rules, or plot contradictions.
Each story was run through all four objectives (STLCS, Canon, Continuity, WIS).
Testing Goals included:
Output Structure Validation
Each objective returned:
- A numerical score (0–100)
- An array of violation objects :rule, reason, conflict, chapter, excerpt
Detection Quality Check:
Verified that known contradictions were mostly flagged (e.g., an item lost in chapter 2 reappearing in chapter 6, or sudden shifts in the defined currency system).
This stage validated not just correctness, but real-world effectiveness; ensuring that the system could handle real narrative text at meaningful scales, while maintaining interpretability and robustness.
Results Presentation
Results were summarized numerically and visually:
Scores: Synthetic Truth Logical Consistency Score (STLCS), Continuity Accuracy Metric (CAM), World Integrity Score (WIS), and Canon Adherence Percentage.
Tables: Extracted claims/facts alongside identified contradictions.
Story 1:
Word count: 39,383.
Canon Adherence Score (CAS): -4738%
Beyond the Canon Adherence Score, the logs shows successful extraction of multiple canon facts.
Examples include:
“Dorothy lives in Kansas”
“The Yellow Brick Road leads to the Emerald City”
“The Scarecrow has no brain”
“The Tin Woodman has no heart”
These are properly recognized as permanent truths of the Wizard of Oz universe, which is correct for canon adherence checks.
Positive observations made while going through the logs were that extracted statements were concise and domain-relevant. Each of the Synthetic Truths were also formatted consistently for embedding and storage.
Few contradictions were also flagged, which could indicate that the book was generally well written with very few contradictions. Although it could also mean false negatives from the LLM.
World Integrity Score (WIE): -4924%
Plot consistency (STLCS): -4195%
The logs show successful extraction of multiple consistency claims such as:
“The Tin Woodman received a new heart made of silk and stuffed with sawdust from the Wizard of Oz.”
“The Wizard promises to give the Scarecrow brains, the Lion courage, and the Tin Woodman a heart.”
“The Cowardly Lion received courage in the form of a liquid from the Wizard of Oz.”
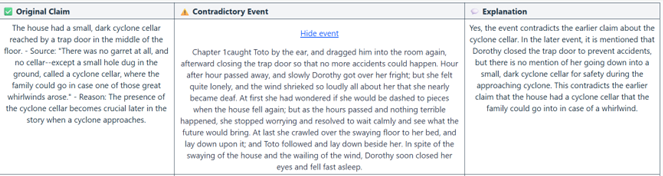
Figure 5-1: Plot Consistency analysis sample on the Wizard of Oz
Positive observations on this particular analysis was that the extracted claims were all consistency relevant.
Continuity accuracy (CAM) : -3900%
The analysis resulted in a -3900% CAM but very little continuity claims were extracted.
“The road through the forest is rough and the yellow bricks are uneven, sometimes broken or missing, creating holes that Toto jumps across and Dorothy walks around.”
Story 2:
Canon Adherence Score (CAS): -2100%
Table 3: A Sample of Canon extracts from The Strange Case of Dr. Jekyll and Mr. Hyde
| CANON FACT | STATUS |
|---|---|
| Dr. Jekyll transforms into Mr. Hyde, two distinct personalities sharing the same body. | Respected |
| Dr. Jekyll's transformation into Mr. Hyde is triggered by a potion. | Respected |
| Mr. Hyde has a strong hatred towards Dr. Jekyll and commits acts of sabotage against him. | Respected |
| Dr. Jekyll experiences physical and mental deterioration due to the constant struggle between his two personalities. | Respected |
| Dr. Jekyll's supply of the potion that allows him to transform is running low, leading to a sense of impending doom. | Respected |
| Dr. Jekyll fears that Mr. Hyde may destroy his written confession if he transforms before it is sealed. | Respected |
| Dr. Jekyll is aware that his time to control his own thoughts and appearance is limited due to the dwindling supply of the potion. | Respected |
| Mr. Utterson's friendship is undemonstrative, founded on a catholicity of good-nature, and he accepts his friendly circle as it comes from opportunity. | Violated |
| The character Lanyon has been exposed to supernatural or extraordinary events that have shaken his beliefs and caused him great distress. | Violated |
The identified violations have been observed to stem from the complex nature of human character where often at times, illogical decisions are made.

Figure 5-2: A Sample Canon Synthetic Truth Extract from The Strange Case of Dr. Jekyll and Mr. Hyde
Plot consistency (STLCS): -2000%
Seventeen Claims were extracted from the text that constituted consistency checks.
A sample of which is
The cheque presented by the man accused of harming the child was genuine, despite suspicions of forgery.
- Source: "I gave in the cheque myself, and said I had every reason to believe it was a forgery. Not a bit of it. The cheque was genuine."
- Reason: This claim is important as it resolves the uncertainty surrounding the authenticity of the cheque and confirms that the accused man did have the means to pay the blackmail amount.
Continuity accuracy (CAM) : -1328%
Dozens of continuity-relevant details were extracted, some of which include:
- Poole describing cabinet footsteps (Chapter 8)
Jekyll creating a will for Hyde (Chapter 10)
Inspectors finding evidence in ashes (Chapter 4)
Lanyon’s deterioration (Chapter 6)
Jekyll’s duality reflections (Chapter 10)
etc
Each fact received a continuity alignment score ranging from 0.736 to 0.772, showing moderate internal consistency recognition.
World Integrity Score (WIE): -1233%
Chapter 6: Discussion and Critical Appraisal of Result
Objective 1 — Plot Consistency (STLCS)
The system successfully extracted factual claims from narrative text and evaluated them for logical contradictions across chapters. This approach aligns conceptually with Veale and Li (2016) who model creativity as modular services and argued that computational agents can detect divergence patterns at scale.
Outcome: The WIE achieved consistent STLCS outputs across test stories, with contradiction detection correctly identifying non-causal reappearances or impossible events (e.g. dead characters returning without explanation).
Novelty: Unlike previous work, which largely focused on creative text generation (Boden, 1998), this system operationalised creativity evaluation—using embeddings for semantic recall and GPT-based causal checks to detect violations.
Limitation: Some contradictions flagged were in fact foreshadowing or plot twists. This highlights the nuanced boundary between true logical contradiction and narrative surprise—a challenge noted also in Jenner et al. (2025).
Objective 2 — Canon Adherence
The hybrid method for detecting canonical truths proved effective, automatically constructing a “world bible” as the story unfolded. This expands on Ekman & Taylor’s (2016) worldbuilding theory by automating the capture of “hard rules” of the fictional world.
Outcome: The model reliably flagged violations such as species behaving outside defined traits or characters contradicting established lore.
Limitation: Canon facts extracted early sometimes conflicted with later retcons. As with real readers, the system lacked the meta-awareness to recognise that the author had intentionally rewritten prior facts.
Critical Note: Azure content policy occasionally blocked LLM responses containing fictional violence, slowing evaluation. This external factor underscores the dependency of the system on commercial API constraints.
Objective 3 — Continuity Accuracy
The continuity accuracy metric tracked states of characters, items, and locations, flagging inconsistencies when previously lost or altered elements reappeared unchanged. This directly complements narrative logic by focusing on temporal coherence.
Outcome: The system accurately logged and compared continuity states, surfacing contradictions like “a broken sword being used again.”
Limitation: Many flagged continuity “errors” were actually deliberate callbacks or flashbacks. This limitation reflects the challenge of distinguishing narrative structure from error—a nuance not addressed in prior work.
Observation: Most identified continuity violations could plausibly serve as future plot developments rather than actual errors. This demonstrates both the sensitivity of the system and the inherent ambiguity in narrative interpretation.
Objective 4 — Worldbuilding Integrity (WIS)
The worldbuilding integrity system measured semantic drift of core world elements (laws, geography, politics, magic systems). This objective represents the most novel contribution, building on Possible Worlds Theory by computationally modelling world coherence as vector deviation.
Outcome: The system highlighted inconsistencies in world laws (e.g. magic working in void space despite earlier rules) and mapped them to underlying rule violations.
Novel Equation:
Equation 7: WIS
This metric is a novel contribution of this research, allowing quantifiable comparison of world integrity between different stories.
Limitation: Lacking baseline expected deviation from human-authored texts, it was challenging to calibrate what counts as “normal drift.”
Comparison to Previous Studies.
The system was built on three theoretical pillars: Narratology, Possible Worlds Theory, and LLM-based cognitive simulation.
Narratology (Alber & Schneider, 2025) framed the narrative as a structured system of analyzable elements (plot events, timelines, arcs). WIE operationalized this by breaking text into discrete claims, storing them as facts, and comparing new events against them.
Possible Worlds Theory (Ekman & Taylor, 2016) views fictional worlds as internally consistent logical systems. WIE applied this perspective to extract and track “Synthetic Truths” (STs), treating them as propositions whose validity should remain stable unless explicitly revised by the author.
LLM-based cognitive simulation (Zhou et al., 2021; Jenner et al., 2025) provided the capability to emulate the human reader’s reasoning — remembering prior context, detecting contradictions, and judging coherence — at scale.
WIE thus embodies these theories by encoding narrative logic in vector embeddings, then using GPT models to apply causal reasoning on retrieved context to verify consistency. This bridges narratology’s theory-driven structures with AI’s pattern-recognition ability, supporting the literature’s call for human-AI synergy (Veale & Li, 2016; Boden, 1998).
Contributions and Novelty
Key Contributions
This research advances the field of narrative analysis and computational world-building through several key contributions. These contributions span theoretical formalisation, novel metrics, architectural design, and tool development, collectively representing a new paradigm for assessing narrative integrity in fictional works.
Formalisation of Narrative Integrity into Four Dimensions
This study introduces a structured framework for evaluating narrative coherence, disaggregating the concept of “story integrity” into four distinct yet interrelated objectives: Plot Consistency (STLCS), Canon Adherence, Continuity Accuracy (CAM), and Worldbuilding Integrity (WIS). Prior studies have typically conflated these elements under general coherence or factual accuracy checks, whereas this work explicitly operationalises them as separate measurable components. This formalisation clarifies the types of errors that can occur in narratives and allows for targeted detection of each category.
Novel Computational Metrics for World Integrity Evaluation
Building upon the conceptual framework, this work proposes new equations for quantifying narrative consistency.
Analogous formulations were designed for CAM and WIS, each measuring distinct forms of logical failure—continuity errors and semantic drift, respectively. These computational metrics represent an original contribution, as no prior systems have provided quantitative indices of narrative world coherence.
Reader-Simulation Paradigm Using LLMs and Embeddings
The system models the cognitive behaviour of a human reader: first extracting key facts, then storing and recalling them, and finally reasoning about new information in light of this knowledge. To achieve this, the engine uses Large Language Models (LLMs) to extract “synthetic truths” (immutable world facts) from text, converts them to embeddings via Azure OpenAI’s text-embedding-ada-002, and stores them in Pinecone for semantic retrieval. This represents a fundamental departure from conventional LLM usage for generative tasks, instead repurposing them for structural logical auditing of fictional worlds.
Persistent World Knowledge Mesh Architecture
A new architectural design was developed for maintaining long-term semantic memories of fictional worlds. This mesh-based knowledge structure stores synthetic truths by category (plot, canon, continuity, world rules) and by story_id, enabling the engine to separate and preserve multiple story worlds concurrently. This design resolves a previously unaddressed issue in narrative evaluation: contamination of facts between unrelated stories.
Interactive Evaluation Interface for Authors
Finally, the system incorporates a React-based frontend that presents detected facts, rules, and violations in an accessible format to non-technical users. This interface transforms abstract logical analyses into actionable feedback, showing authors exactly where contradictions and gaps occur on a chapter-by-chapter basis. By making the tool usable for real-world writing workflows, this contribution bridges the gap between theoretical research and practical application.
Further Work
The current implementation operates as a standalone evaluator, processing uploaded stories and producing diagnostic reports. Future work will involve evolving this tool into a comprehensive world-building platform. Such a platform would:
Maintain persistent world meshes, where all synthetic truths discovered about a fictional universe are stored and versioned.
Police contributions to shared worlds, warning authors if their additions violate the foundational rules of the world.
Support preconfigured foundational meshes that could be sold or licensed to authors, allowing them to build within established fictional universes with built-in guardrails.
Enable a marketplace of prebuilt worlds, allowing creators to acquire richly detailed universes and extend them consistently.
Integrate visual world-mapping features to show the structure and strength of a world’s logic as it evolves over time.
Expand the implementation to movie and game scripts.
With more budget to work with, longer test cases on published works could be performed on better LLM versions.
Critical Appraisal
The results support that WIE achieves its objectives, aligning with theoretical expectations from narratology and cognitive science. While not flawless, its capability to detect diverse forms of narrative inconsistency demonstrates a proof of concept that AI can shoulder the cognitive burden of world consistency tracking for authors.
This represents a step toward the literature’s vision of human-AI creative collaboration (Zhou et al., 2021), with WIE contributing the logical rigor while authors focus on creativity.
It is important to also note that the World Integrity Engine (WIE) does not evaluate the quality of a story, but the integrity of the world that hosts it. In this framework, the fictional world exists as a foundation — a persistent structure of physical laws, species traits, histories, geographies, and social systems — while the story is merely a temporary sequence of events occurring upon that foundation. The world precedes the story’s genesis and endures beyond its conclusion. By separating the two, the WIE treats the story as an expression of how consistently that foundation is upheld.
When violations are flagged, they are not necessarily errors in storytelling, but rather signs of structural thinness in the underlying world model. Many such points are in fact creative openings — “vacant lots” in the foundation or “low hanging fruits” — where authors could insert new lore or causal rules to reinforce the world. In this sense, the WIE is not dismantling stories, but highlighting where the foundation could be expanded. This reframes high violation counts not as failures, but as markers of where the world’s logical architecture is least developed and therefore most ripe for creative growth.
Chapter 7: Conclusion
This dissertation set out to design, implement, and evaluate the World Integrity Engine (WIE) — a system that automates the evaluation of logical consistency in fictional narratives. Drawing on structural narratology, Possible Worlds Theory, and LLM-based cognitive simulation, the system assessed stories on four dimensions: Plot Consistency (STLCS), Canon Adherence, Continuity Accuracy (CAM), and Worldbuilding Integrity (WIS).
Through iterative design and testing, the WIE successfully demonstrated that large language models, when combined with semantic memory (vector embeddings) and structured reasoning workflows, can emulate the reader’s mental process of recalling prior facts, comparing them to new events, and judging their coherence. This validates the theoretical argument that AI can act as a cognitive support tool for authors, relieving them of the intensive memory burden involved in maintaining large fictional worlds.
Chapter 8: ETHICS APPROVAL
Data Security: All data pertaining to a story are stored securely in a database accessible only through author account login.
Data manipulation: Authors maintain complete control over their stories. The AI only serves to assist in holding it together but never making additions.
The author of this paper completed a Research and Professional Ethics course. Below is the author’s certificate

Figure 8-1
Research and Professional Ethics Certification of Completion
Chapter 9: References
All sources referenced throughout this document, including literary works, academic research, software frameworks, and online resources.
- Dungeons & Dragons (2025).
- Fantastic Beasts (2025).
- Game of Thrones (2025).
- Harry Potter and the Cursed Child (2025).
- Ipsos | Global Market Research and Public Opinion Specialist (2025). Available at: https://www.ipsos.com/en-uk (Accessed: Sep 16, 2025).
- The Lord of the Rings (2025).
- Quidditch Through the Ages (2025).
- Star Wars (2025a).
- Star Wars (2025b).
- synthetic (2025).
- The Tales of Beedle the Bard (2025).
- Truth (2025).
- Eriador (2024).
- Azure’s text-embedding-ada-002. Available at: https://ai.azure.com/catalog/models/text-embedding-ada-002 (Accessed: Sep 17, 2025).
- Harry Potter | Official home of Harry Potter (a). Available at: https://www.harrypotter.com/ (Accessed: Sep 15, 2025).
- Harry Potter | Official home of Harry Potter (b). Available at: https://www.harrypotter.com/ (Accessed: Sep 16, 2025).
- Homepage | University of Southampton. Available at: https://www.southampton.ac.uk/ (Accessed: Sep 16, 2025).
- Napkin AI – The visual AI for business storytelling. Available at: https://www.napkin.ai (Accessed: Sep 19, 2025).
- Pinecone. Available at: DataCamp Pinecone Tutorial (Accessed: Sep 17, 2025).
- React v19 – React. Available at: https://react.dev (Accessed: Sep 17, 2025).
- Tailwind CSS. Available at: https://tailwindcss.com/ (Accessed: Sep 17, 2025).
- Vite. Available at: https://vite.dev (Accessed: Sep 17, 2025).
- Alber, J. and Schneider, R. (2025) The Routledge Companion to Literature and Cognitive Studies. Taylor & Francis.
- Boden, M.A. (1998) ‘Creativity and artificial intelligence’, Artificial Intelligence, 103(1), pp. 347–356. Available at: https://doi.org/10.1016/S0004-3702(98)00055-1 .
- Wolf, M.J.P. (2014) Building Imaginary Worlds: The Theory and History of Subcreation. New York: Routledge.
Appendices
Evaluator.py
from openai import AzureOpenAI
from core.lore_engine import store_fact, search_nearby, setup_logger,clear_vectors
from core.openai_api_settings import openai_api_settings as cfg
import re
import logging
import os
# Initialize Azure client once using your config
client = AzureOpenAI(
api_key=cfg["api_key"],
api_version=cfg["api_version"],
azure_endpoint=cfg["api_base"]
)
def reset_storage():
clear_vectors()
print("Reset Complete")
return 0
# OBJECTIVE 1
def split_into_chunks(text, max_words=1000):
print("Starting splitting by chapters and chunks.")
# Detect chapters — common pattern: "Chapter 1", "CHAPTER TWO", etc.
chapter_pattern = r"(Chapter\s+\d+|CHAPTER\s+\w+)"
parts = re.split(chapter_pattern, text, flags=re.IGNORECASE)
chunks = []
for i in range(1, len(parts), 2): # Skip even indexes (before first match)
chapter_title = parts[i].strip()
chapter_text = parts[i + 1].strip() if i + 1 < len(parts) else ""
# Break chapter into smaller chunks
words = chapter_text.split()
for j in range(0, len(words), max_words):
chunk_text = " ".join(words[j:j + max_words])
chunks.append((chapter_title, chunk_text))
return chunks # Returns list of (chapter, chunk) tuples
def extract_critical_claims(chunk):
print("Starting Truth extraction.")
system_prompt = "You are a logic assistant. Extract all critical factual claims made by characters or narration that, if contradicted later, would break the story logic.\nRespond in this format:\n- Claim: <factual statement>\n- Source: <quote or scene>\n- Reason: <why it's important>"
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": chunk}
],
temperature=0
)
return response.choices[0].message.content.split("\n- Claim: ")[1:]
def is_contradiction(claim, new_event):
prompt = f"Earlier claim: {claim}\nLater event: {new_event}\nDoes the event contradict the claim without explanation? Why?"
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": "You judge contradictions between story events."},
{"role": "user", "content": prompt}
],
temperature=0
)
return response.choices[0].message.content if "yes" in response.choices[0].message.content.lower() else None
# OBJECTIVE 2
def extract_canon_facts(chunk):
"""
Extract canonical world facts (synthetic truths) from a story segment using LLM inference.
These include species traits, magic laws, restrictions, rules, etc.
"""
prompt = """
You are an assistant designed to extract canonical world-building facts from a fictional story.
These are statements that define unchanging rules or limitations in the fictional world.
Extract only the most authoritative and permanent facts (laws of nature, race traits, etc.).
Return your response in this format:
- Canon Fact: <fact>
Examples:
- Canon Fact: Zaratans are blind and rely on echolocation
- Canon Fact: Sun mana requires exposure to direct sunlight
- Canon Fact: No human can breathe on Mars without a suit
- Canon Fact: Only the High Priest can activate the gate
Now extract canonical facts from this excerpt:
"""
try:
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": chunk}
],
temperature=0.2,
max_tokens=512,
)
output = response.choices[0].message.content
canon_facts = []
for line in output.strip().split("\n"):
if line.strip().lower().startswith("- canon fact:"):
canon_facts.append(line.split(": ", 1)[1].strip())
return canon_facts
except Exception as e:
print(f"[CanonExtractor] Failed on chunk with error: {e}")
return []
def is_canon_break(canon_fact, story_segment):
"""
Determines if a new story segment contradicts a known canon fact.
Uses GPT reasoning to make a judgment.
"""
prompt = f"""
Canon Fact: {canon_fact}
Story Segment: {story_segment}
Does the story segment contradict the canon fact without explanation?
Be specific and justify your answer.
"""
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": "You are a strict world logic checker. Identify when fictional canon is broken."},
{"role": "user", "content": prompt}
],
temperature=0
)
content = response.choices[0].message.content.strip()
return content if "yes" in content.lower() else None
# OBJECTIVE 3
def extract_world_rules(chunk):
"""
Extract key rules and principles that define the logic, physics, economics,
or magic system of a fictional world. These are used to assess internal integrity.
"""
prompt = """
You are an assistant that identifies core worldbuilding rules from fictional text.
Extract only stable, general laws that define how the fictional world works.
Return your output in this format:
- World Rule: <the rule or law>
Examples:
- World Rule: Gravity magic only works near the crystal spires.
- World Rule: Currency is measured in ember coins and flint shards.
- World Rule: The moon reflects light but produces none of its own.
- World Rule: Wards must be drawn in blood to function.
Now extract worldbuilding rules from this excerpt:
"""
try:
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": chunk}
],
temperature=0.3,
max_tokens=512,
)
output = response.choices[0].message.content
rules = []
for line in output.strip().split("\n"):
if line.strip().lower().startswith("- world rule:"):
rules.append(line.split(": ", 1)[1].strip())
print(f"[World Rules:] {rules}")
return rules
except Exception as e:
print(f"[WorldRuleExtractor] Failed on chunk with error: {e}")
return []
def is_integrity_break(rule, chunk):
"""
Determines if a story segment breaks a foundational worldbuilding rule.
"""
prompt = f"""
Worldbuilding Rule: {rule}
Story Segment: {chunk}
Does the story segment contradict or violate this worldbuilding rule without clear justification?
Be precise and explain if so.
"""
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": "You are an expert in fictional world logic. Find when rules are broken."},
{"role": "user", "content": prompt}
],
temperature=0
)
content = response.choices[0].message.content.strip()
return content if "yes" in content.lower() else None
def extract_continuity_facts(chunk):
"""
Extract continuity-relevant facts (timelines, object states, character attributes).
"""
prompt = """
You are a continuity assistant for fictional stories. Your job is to extract key facts about events, characters, objects, and states that need to remain consistent throughout the story.
Extract facts like:
- Injuries, deaths, lost items
- Time-sensitive events or countdowns
- States of objects (damaged, missing, used)
- Character traits, knowledge, or decisions
Return results in this format:
- Continuity Fact: <description>
Now extract continuity facts from the following excerpt:
"""
try:
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": chunk}
],
temperature=0,
max_tokens=512,
)
output = response.choices[0].message.content
facts = []
for line in output.strip().split("\n"):
if line.strip().lower().startswith("- continuity fact:"):
facts.append(line.split(": ", 1)[1].strip())
return facts
except Exception as e:
print(f"[ContinuityExtractor] Failed on chunk with error: {e}")
return []
def is_continuity_break(past_fact, new_segment):
"""
Determines if a new story segment contradicts a known continuity fact.
"""
prompt = f"""
Continuity Fact: {past_fact}
Story Segment: {new_segment}
Does the story segment contradict this continuity fact without justification?
Be precise and explain your reasoning.
"""
response = client.chat.completions.create(
model=cfg["chat_model"],
messages=[
{"role": "system", "content": "You are a continuity supervisor. Identify contradictions in timeline, character, or state."},
{"role": "user", "content": prompt}
],
temperature=0
)
content = response.choices[0].message.content.strip()
return content if "yes" in content.lower() else None
# CORE FUNCTIONS
def evaluate_plot_consistency(text, story_id="default"):
plot_consistency_logger = setup_logger("plot_consistency", str(story_id))
print("Starting Evaluation of plot consistency.")
plot_consistency_logger.info(f"Starting Evaluation of plot consistency...")
chunks = split_into_chunks(text)
all_claims = []
violations = []
for i, (chapter_title, chunk) in enumerate(chunks):
claims = extract_critical_claims(chunk)
for c in claims:
store_fact("plot", c, chapter=chapter_title, story_id=story_id)
all_claims.append((i, c))
print(all_claims)
plot_consistency_logger.info(f"[ All Claims ]: {all_claims}")
for i, chunk in enumerate(chunks):
for j, (ci, claim) in enumerate(all_claims):
if ci < i:
results = search_nearby("plot", claim, story_id=story_id)
for match in results:
contradiction = is_contradiction(claim, chunk)
if contradiction:
violations.append({
"claim": claim,
"conflict": chunk[:300],
"reason": contradiction
})
total = len(all_claims)
score = 100 - ((len(violations) / total) * 100) if total > 0 else 100
plot_consistency_logger.info(f"[ Score ] : {score}")
plot_consistency_logger.info(f"[ Violations ] : {violations}")
return {
"score": round(score),
"violations": violations,
"all_claims": all_claims
}
# Placeholder scores for other objectives (to be implemented)
def evaluate_continuity_accuracy(text):
continuity_logger = setup_logger("continuity", text[:10])
print("Starting Evaluation of continuity accuracy.")
continuity_logger.info(f"[Starting Evaluation of continuity accuracy.] :")
chunks = split_into_chunks(text)
# Step 1: Extract and store continuity facts
for i, (chapter_title, chunk) in enumerate(chunks):
continuity_facts = extract_continuity_facts(chunk)
for fact in continuity_facts:
store_fact("continuity", fact, chapter=chapter_title, story_id="default")
# Step 2: Search relevant continuity facts
all_facts = search_nearby(category="continuity", text="continuity", top_k=50)
continuity_logger.info(f"[Continuity Facts: ] {all_facts}")
print(f"[All Continuity Facts: ] {all_facts}")
total_extracted_facts = [match["metadata"]["text"] for match in all_facts]
# Step 3: Check for continuity breaks
violations = []
for chunk in chunks:
for match in all_facts:
continuity_text = match["metadata"]["text"]
contradiction = is_continuity_break(continuity_text, chunk)
if contradiction:
violations.append({
"claim": continuity_text,
"conflict": chunk[:300],
"reason": contradiction
})
score = 100 - ((len(violations) / len(all_facts)) * 100) if all_facts else 100
continuity_logger.info(f"[ Score ] : {score}")
continuity_logger.info(f"[ Violations ] : {violations}")
return {"score": round(score), "violations": violations, "total_extracted_facts":total_extracted_facts}
def evaluate_canon_adherence(text, story_id="default"):
canon_logger = setup_logger("canon_adherence", str(story_id))
print("Starting Evaluation of canon adherence.")
print(f"[STORY ID] Using story_id: {story_id}")
canon_logger.info("Starting Evaluation of canon adherence.")
canon_logger.info(f"[STORY ID] Using story_id: {story_id}")
chunks = split_into_chunks(text)
# Step 1: Extract and store canon facts from current story
for i, (chapter_title, chunk) in enumerate(chunks):
canon_facts = extract_canon_facts(chunk)
print(canon_facts)
canon_logger.info(f"[Chapter: {chapter_title}] Extracted canon facts: {canon_facts}")
for fact in canon_facts:
store_fact("canon", fact, chapter=chapter_title, story_id=story_id)
# Step 2: Search stored canon facts
canon_vectors = search_nearby(category="canon", text="canon", top_k=50, story_id=story_id)# or get_all_canon_facts()
print(canon_vectors)
canon_logger.info(f"Retrieved {len(canon_vectors)} canon vectors for comparison.")
# Step 3: Check each chunk against canon
violations = []
for chunk in chunks:
for match in canon_vectors:
canon_text = match["metadata"]["text"]
print("This is the texts being checked: ",canon_text)
canon_logger.debug(f"Checking canon text: {canon_text[:80]}... against chunk {chapter_title}")
contradiction = is_canon_break(canon_text, chunk)
if contradiction:
violations.append({
"claim": canon_text,
"conflict": chunk[:300],
"reason": contradiction
})
canon_logger.warning(f"Violation found in {chapter_title}: {violations}")
score = 100 - ((len(violations) / len(canon_vectors)) * 100) if canon_vectors else 100
canon_logger.info(f"[ Score ] : {score}")
canon_logger.info(f"[ Violations ] : {violations}")
return {"score": round(score), "violations": violations, "canon_facts": canon_facts}
def evaluate_worldbuilding_integrity(text):
wbi_logger = setup_logger("world_building_integrity", text[:10])
print("Starting Evaluation of worldbuilding integrity.")
wbi_logger.info(f"Starting Evaluation of worldbuilding integrity...")
chunks = split_into_chunks(text)
# Step 1: Extract and store world rules
for i, (chapter_title, chunk) in enumerate(chunks):
rules = extract_world_rules(chunk)
print(f"[WorldRules] {chapter_title}: {rules}")
wbi_logger.info(f"[WorldRules] {chapter_title}: {rules}")
for rule in rules:
store_fact("integrity", rule, chapter=chapter_title, story_id="default")
# Step 2: Retrieve all known rules
integrity_vectors = search_nearby(category="integrity", text="rule", top_k=50)
# Step 3: Evaluate each chunk against stored world rules
violations = []
for chunk in chunks:
for match in integrity_vectors:
rule = match["metadata"]["text"]
contradiction = is_integrity_break(rule, chunk)
if contradiction:
violations.append({
"rule": rule,
"conflict": chunk[:300],
"reason": contradiction
})
score = 100 - ((len(violations) / len(integrity_vectors)) * 100) if integrity_vectors else 100
wbi_logger.info(f"[ Score ] : {score}")
wbi_logger.info(f"[ Violations ] : { violations }")
return {
"wis": round(score),
"violations": violations,
"rules": rules
}
Lore_engine.py
from pinecone import Pinecone, ServerlessSpec
from openai import AzureOpenAI
from core.openai_api_settings import openai_api_settings as cfg
import logging
import os
# Initialize Azure OpenAI client
client = AzureOpenAI(
api_key=cfg["api_key"],
api_version=cfg["api_version"],
azure_endpoint=cfg["api_base"]
)
def embed_text(text):
response = client.embeddings.create(
model=cfg["embedding_model"],
input=[text]
)
return response.data[0].embedding
# Pinecone setup
pc = Pinecone(api_key="XXX")
# Create index if it doesn't exist
if "wie-index" not in pc.list_indexes().names():
pc.create_index(
name="wie-index",
dimension=1536,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
# Get Pinecone index
index = pc.Index("wie-index")
# Store a fact in Pinecone
def store_fact(category, text, chapter, story_id="default"):
vector = embed_text(text)
metadata = {
"category": category,
"chapter": chapter,
"text": text,
"story_id": story_id
}
index.upsert([(f"{story_id}-{category}-{chapter}-{hash(text)}", vector, metadata)])
def clear_vectors():
try:
# Defensive: check index still exists
if "wie-index" not in pc.list_indexes().names():
# Recreate fresh index
pc.create_index(
name="wie-index",
dimension=1536,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
else:
# If it exists, just clear vectors
index.delete(delete_all=True)
except Exception as e:
print(f"Error clearing vectors: {e}")
raise
# Search nearby facts in Pinecone
def search_nearby(category, text=None, vector=None, top_k=3, story_id="default"):
"""
Search for similar stored facts in Pinecone.
If a vector is provided, use it directly; otherwise embed from text.
"""
if vector is None:
if text is None:
raise ValueError("Either `text` or `vector` must be provided.")
vector = embed_text(text)
results = index.query(vector=vector, top_k=top_k, include_metadata=True)
return [
r for r in results['matches']
if r['metadata'].get('category') == category and r['metadata'].get('story_id') == story_id
]
def setup_logger(name, book_title, log_dir="logs"):
"""
Create and return a logger that writes to a file named after the book.
Example: logs/<book_title>_<name>.log
"""
# Ensure logs directory exists
os.makedirs(log_dir, exist_ok=True)
# Clean up book title (no spaces/special chars in filenames)
safe_title = "".join(c if c.isalnum() or c in ("_", "-") else "_" for c in book_title)
log_filename = os.path.join(log_dir, f"{safe_title}_{name}.log")
logger = logging.getLogger(f"{name}_{safe_title}")
logger.setLevel(logging.INFO)
# Avoid adding multiple handlers if already exists
if not logger.handlers:
fh = logging.FileHandler(log_filename, encoding="utf-8")
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger